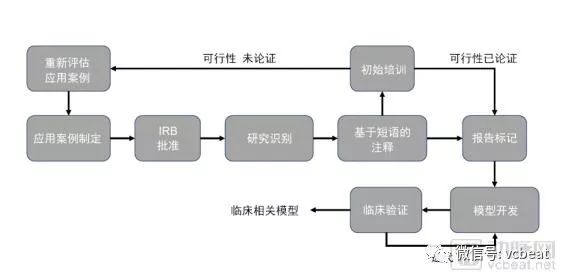
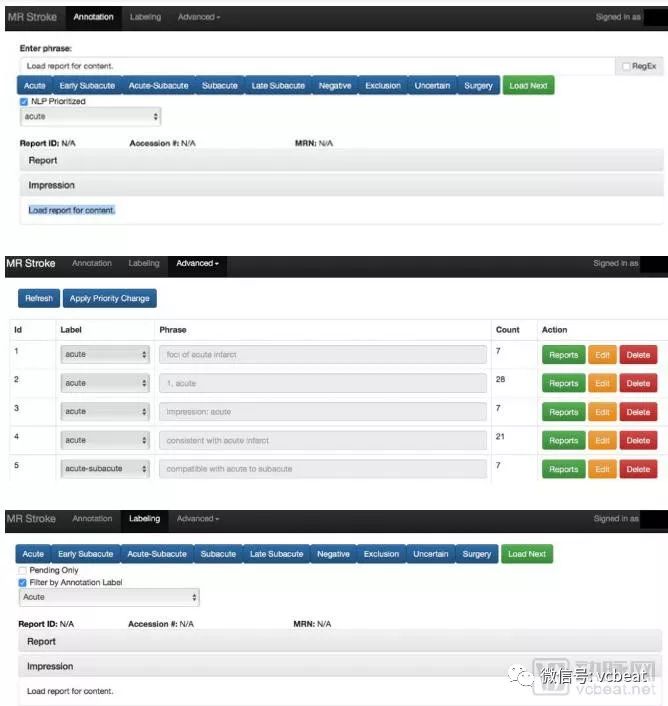
Insomnia has become a common problem. It is difficult to cure and complicated. It is very difficult to study. According to data from the Centers for Disease Control and Prevention, more than one-third of American adults lack sleep. Usually, doctors perform sleep monitoring on patients by wearing traditional sensors such as chest straps, nasal probes, and brain electrodes. These uncomfortable ways lead to insomnia itself, so the data collected is not representative. To provide better sleep for patients, researchers at the Massachusetts Institute of Technology and Massachusetts General Hospital, in conjunction with NVIDIA, use AI and Wi-Fi-like signals to monitor patients without wearing any sensors. The researchers installed special wireless devices in the bedroom so the monitored staff could sleep at home. The device collects signals reflected from the monitored object and sends the data back to the researcher via the cloud. By understanding how people in the bedroom affect RF, and analyzing the measurements of pulse, respiratory rate, and motion, researchers can determine different stages of sleep: mild sleep, deep sleep, rapid eye movement, or awake. In addition, the researchers conducted a study of 25 people sleeping on 100 nights. The sleep mark is performed every 30 seconds, and the data for training is separated from the data for testing. Its cloud-based services can remotely collect signals and run algorithmic models. Researchers at the Massachusetts Institute of Technology use NVIDIA GPUs for model training and reasoning on back-end cloud services. In addition, they used NVIDIA's cuDNN library and TensorFlow deep learning framework. Sleep stage research has a wide range of applications, and this sleep stage detection technique can be used to monitor diseases such as depression. This application case shows people to see the new application scenario of “AI+ Medical â€. From research to clinical AI applications Today, deep learning technology is gradually evolving from research to clinical applications in the medical field. The types of data involved also range from radiology and pathology data to other types of clinical data such as electronic medical records, hospital operations, and genetic data. However, in hospitals, the training and use of AI algorithms is still not mature enough. The reason is that using deep learning to create clinical impact requires more than just cutting-edge algorithms, but also some key components: Clinicians need to be involved from the beginning of the project to clarify the use of the AI ​​model; Access to annotated clinical data sets; Develop a machine learning model; Integrated into the clinical workflow; Infrastructure for model deployment; Validation in real-world clinical settings. Based on this, NVIDIA, the world's top GPU company, and the MGH & BWH Clinical Data Science Center (hereinafter referred to as the CCDS Center) in Boston, Massachusetts, have summarized a scientific AI project training cycle. It is reported that the typical project cycle of CCDS is based on clinical feedback such as continuous input from radiologists and frequent assessments of recent studies. In the typical project cycle of CCDS, the specialized hardware infrastructure is critical to the training of the AI ​​model as it is the basis for the entire model development and deployment. Hospital clinical systems have limited computing power requirements, and hospitals prefer to use systems with high reliability and long uptime to meet moderate computing and data access requirements. The high-speed GPU, high-speed network connectivity, high-performance storage, and the broadband access model required to train neural networks far exceed the capabilities of hospital IT teams. For clinical applications of deep learning, the hardware infrastructure must meet its computational requirements. The flaws in most hospitals in high-performance computing infrastructure are seriously hampering the implementation of AI projects. This article is an excerpt from the white paper from Nvidia's "Deep Learning Model for Developing Hospitals: A Case Study of the Clinical Data Science Center." From this, you will learn how NVIDIA cooperates with the CCDS center to utilize its high-performance computing advantages to solve various problems in image processing and initial model development, large-scale model training, and clinical verification in the AI ​​model training process. Image processing and initial model development Once the research was annotated, the CCDS team began early model development. The first step in the process is to turn the research into an easy-to-use file format. Images were copied from clinical PACS by studying vendor neutral archiving to minimize the risk of the clinical system. The image is then saved in a directory in the network storage solution, and permissions are limited to those listed on the approved IRB application. Capacity data (eg, MR, CT, etc.) is typically converted from DICOM (the standard medical imaging format used by PACS) to NIFTI (a file format). The CCDS team marks research from radiology reports through custom-developed web applications. The phrase is first assigned a soft label (top) by phrase-based matching, the phrase is re-prioritized and quality assessed (middle). Finally, the CCDS team will study the manual confirmation soft label (bottom) one by one. The initial stages of model development also follow an interactive workflow. In these interactive sessions, the CCDS team develops the model and trains it for a certain period of time to ensure functional correctness. Due to PHI concerns, the CCDS team must remotely launch these interactive sessions in the partner's data center to ensure that PHI is stored locally on easily removable hardware. This environment is intended to be used as a scaled-down version of the CCDS computing cluster. Therefore, the CCDS team will assign two to four high-performance GPUs (NVIDIA Tesla P100 or Tesla V100) to each machine learning scientist, supporting GPUDirect P2P for efficient intra-node communication and GPUDirect RDMA for inter-node communication. These features are very advantageous when training models on capacity data and have proven to be both highly computationally and memory intensive. 16GB of high-speed HBM2 memory, support for half-precision floating-point operations, and TensorCore mixed-precision matrix multiply/add (Tesla V100 only) dramatically reduces the hardware required relative to consumer GPUs. These benefits are reflected in the entire CCDS infrastructure. Although high performance is not required during the early model development phase, these features must be available in the development environment during cluster operation to ensure the correctness of the model. Currently, the CCDS team is exploring two ways to support this workflow: 1. Static hardware allocation: Each machine learning scientist is equipped with a dedicated machine, a physical machine or a virtual machine, on which all explorations of image normalization techniques and initial model development can be performed. 2. Dynamic hardware allocation: Nodes are assigned from high priority queues through the cluster's scheduler. Individual requests for the second node are highly unprioritized relative to the first request. Large scale model training Once a set of candidate architectures has been identified, the CCDS team uses CCDS's computational clusters for large-scale training. Although the same hardware is used, most of these operations are performed in two steps: 1. Hyperparametric Search: Test candidate architectures with a variety of hyperparameter configurations to determine the best model configuration. It depends on the scientist's preference or is determined by random search or Bayesian Optimization. By leveraging the cluster's excess capacity, a large number of configurations can be tested in parallel, transforming a series of tasks that previously tested various architectures and configurations into a parallel task, which allows the AI ​​model to be iteratively optimized and optimized. 2. Large-scale training: Once a limited set of model architectures and hyperparameter configurations have been identified, each model is trained to achieve convergence and try to determine the best model in the group. Successful large-scale training relies on parallelizing models in GPUs with efficient inter-node communication. In response, the CCDS team designed the cluster to accommodate the needs of the workflow. The compute nodes are stored behind IBM's LSF scheduler, delegating the submitted work to available resources and ensuring a reasonable distribution of nodes. Submit work through the Docker container to manage the development environment and ensure consistency, simplifying the management of the number of packages and the number of packages installed on each node. The CCDS team recently received the world's first Volta-type DGX-1 system With an easy-to-use, containerized environment, CCDS has been able to parallelize work across multiple nodes and GPUs with TensorFlow transparent synchronization operations and custom internal libraries. The CCDS team also relies heavily on NVIDIA's NCCL library, which is integrated into the framework for efficient multi-GPU operation. This tool allows the team to reduce training time and shorten the model development cycle. Clinical verification Clinical validation of models and tools is a key step in the development process of the CCDS team. In an academic context, a model is considered successful if it can perform more than three to four radiologists on the test set. The CCDS team is focused on creating tools that clinicians can use to diagnose patients, and a rigorous validation process is in place to ensure that the model is clinically viable. 1, pre-deployment verification Model validation begins during model development. The CCDS team works with clinicians to create groups and training sets. The CCDS team and doctors have collected a vast collection of training sessions that are not only clear and ideal images that are positive or negative for a particular disease, but also ensure that low-quality studies are explained (eg, sweeper movement or image artifacts) And studies that are considered to be "difficult" to read (eg, simulation, atypical anatomy, and post-operative follow-up). In order to perform further stress testing on the model, the CCDS team evaluated it from a coherent study obtained from a hospital scanner. With a large number of images available every day, the CCDS team is able to continuously test the model throughout the development cycle. 2. Verify after deployment After integration with the hospital's clinical system, the CCDS team needs to evaluate the model in the day-to-day operations of the clinician. This process helps evaluate: Model performance: Does the model perform well in the reading room and meet the radiologist's expectations? Ease of use: Does the model and its user interface improve the effectiveness and efficiency of clinical workflows? In this regard, the CCDS team worked with clinical partners to test the performance of the model and the ease of use of the tool in a highly collaborative and iterative process. The software and user interface developers of the CCDS team continue to observe the clinician's situation in order to understand how the tool is being used throughout the reading room. Because different clinicians have different subtle workflow differences, the CCDS team makes changes to departments rather than specific radiologists to optimize ease of use. This not only improves the likelihood that the model will improve the performance of the clinician rather than inhibiting its performance, but it will also help to drive adoption. As more radiologists use the tool to get more feedback, the team can further improve the model and create a virtuous circle. The scanner, its sequence, its imaging solution, and its reconstruction algorithms are constantly changing, and the team is not always aware of the upgrade of these software or hardware. Therefore, continuous monitoring is required to ensure that model performance does not degrade. Although manual feedback loops can be applied, such procedures are prone to errors and add to the workload and additional responsibilities of the radiologist. To eliminate this dependency and minimize the burden on the clinician, the CCDS team automates the process; all model outputs are recorded along with the radiologist's report. Run the analysis to assess the performance of the model over time and mark significant changes. Given the potentially significant impact of downtime on patient care, the hospital intends to be more conservative in adopting new technologies. Therefore, it is critical that any new solution be thoroughly validated prior to integration and that the solution is very beneficial in keeping with existing workflows. While the advent of deep learning medicine has brought many new challenges to frontline work, the CCDS team found that the combination of creativity, alertness, and careful selection of supplier solutions can overcome these difficulties. What technical support does NVIDIA provide? In the entire CCDS project, the AI ​​technology provided by NVIDIA plays a vital role, including the following important technologies: 1. High-performance GPU (Nvidia Tesla P100 or Tesla V100) that supports GPUDirect P2P for efficient intra-node communication and GPUDirect RDMA for inter-node communication. 2. Cluster Infrastructure: The high-performance DGX-1 provides a powerful computing platform. When connected to high-speed Infiniband, individuals can efficiently train large batches of large models on volumetric medical data. 3, Nvidia-docker can seamlessly integrate the GPU into the latest 2.0 release of the container, further reducing friction. Other benefits that CCDS has achieved include the ease of selection of the Tensorflow release, which typically requires a special version of Nvidia's highly optimized cuDNN library; the flexibility of choosing a base container, including non-Nvidia containers (if needed); and an easy way to separate GPUs. If you are an entrepreneur or investor in the medical AI field, we strongly recommend that you download this white paper to learn more about how NVIDIA is based on high-performance computing to solve the challenges of the AI ​​model in the entire hospital training cycle. ESU pencil,Monopolar cautery pencil,Diathermy pencil,Bovie pencil 2 MEDS TECHONOLOGY CO.,LTD , https://www.2-meds.com